本章将对强化学习方法做一个统一的描述,包括:
基于模型的方法(model-based),如动态规划与启发式搜索。
无模型的方法(model-free),如蒙特卡洛和时序差分。
基于模型的方法主要依赖于 planning ,而无模型的方法则依赖于 learning
这些方法既相似又不同,但它们的核心都是 值函数的计算。
所有的方法都遵循:观察未来时间,计算树状值,然后使用值作为更新目标来优化逼近值函数。
8.1 Models and Planning
一个模型可以告诉我们 agent 所需要用到的一切,来预测环境将会对 agent 的 actions 产生怎样的回应。
给定一个 状态-动作 对,模型会给出 next state and next reward.
随机模型意味着 next state and next reward 存在多种可能,各有其概率。
分布模型(distribution models) 会给出所有这些可能及相应的概率的描述。
采样模型(sample models) 则给出采样自这个概率分布中的其中一种可能。
动态规划中用到的模型 $p(s’,r|s,a)$ 就是一个分布模型。
在第 5 章中的例子 blackjack 中用到的就是采样模型。
分布模型显然比采样模型更强,因为我们可以用分布模型轻松得到采样。
当然,在某些情形下得到一个采样模型会相对容易得多。
模型可以用来模拟产生经历。
给定一个初始状态和动作,采样模型会给出一个可能的转移,而分布模型会给出所有可能转移及概率。
如果给定一个初始状态和策略,那么采样模型能够生成一整个 episode,而分布模型能给出状态转移树状图(包含所有可能的 episode 及其概率)。
我们可以说模型是用来模拟环境,或者说用来产生模拟经历的。
planning 在这里表示一个计算过程,以一个模型为输入,通过与模型化的环境交互,来产生或优化一个策略。
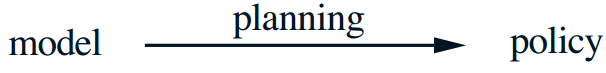
根据这个定义,在人工智能领域,有两个不同的方法来进行 planning
State-space planning: 其包含了本书的方法,主要为通过在状态空间中搜索来得到最优策略或达到目标的最优路径,动作导致状态的转移,从而计算值函数。
Plan-space planning: 改为在 plan space 中搜索。
Plan-space 方法难以有效应用在随机序贯决策中(Russell and Norvig,2010)
本章将描述所有 state-space planning 方法的一个统一的构造。
其主要基于两点:
- 都将计算值函数作为优化策略的关键中间步骤;
- 计算值函数的方法,都是借由模拟经历来执行 update or backup.

动态规划完美切合该结构,本章后面介绍的方法也都符合该结构。区别仅在于做何种更新、以如何顺序执行以及信息保留时间的长短。
统一视角更加强调方法之间的关系。
planning and learning 的核心都是对值函数的估计。
区别仅在于 planning 用的是模拟经历,而 learning 用的是实际经历。
当然,这个区别会导致一些其它的差别,比如如何分配性能以及如何灵活地产生经历。
而统一的结构能够使我们共用两种方法的某些 ideas.
本章另一个主题就是关于 planning 在 small, incremental steps 中的优点。
这使得 planning 能够在任意时刻被打断或重定向,减小计算的损耗。
8.2 Dyna: Integrated Planning, Acting, and Learning
当 planning 在线完成时,会在与环境的交互中产生一些有趣的问题。
在交互过程中得到的一些新的信息可能会改变模型,由此与 planning 发生关系。
因此在考虑当前乃至未来的状态与决策时,有必要定制 planning 的过程。
而如果决策和模型学习都消耗较大的计算力,那么可用计算力就需要合理分配。
本节引入的 Dyna-Q,是一个简单的结构,它集合了一个在线规划代理所需的主要功能。
在 Dyna-Q 中出现的每个功能都是简单甚至破碎的形式。
后续会精心设计这些功能,并做出权衡。
在一个 规划代理 中,实际经历至少有两个功能:一是改善模型,二是直接优化值函数和策略。
前者称作 model learning ,有时也叫作 indirect reinforcement learning;
后者称作 direct reinforcement learning.
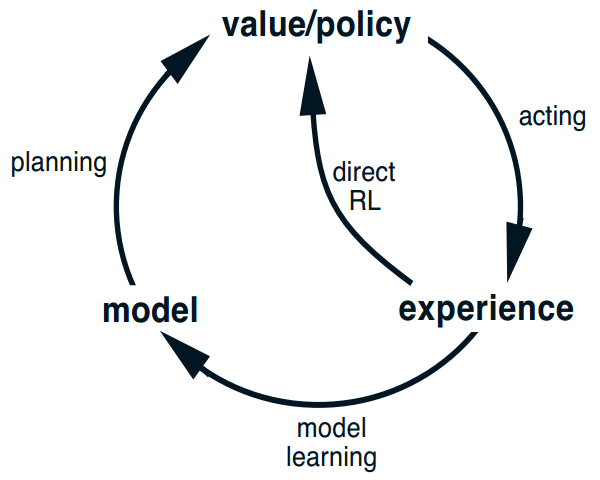
使用模型的优点是 能够以更少的环境交互,更有限的实际经历 来达到更优的策略。
而使用模型的缺点在于 复杂的模型设计,以及其与实际环境的偏差造成的影响。
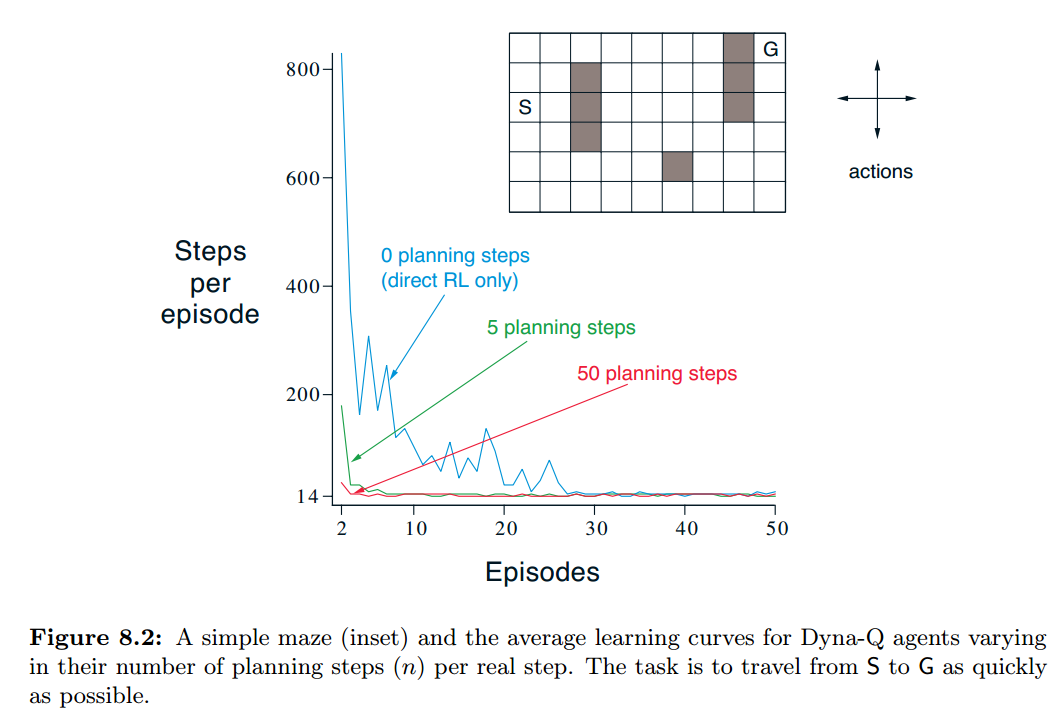
类似单步 Q-learning,Dyna-Q 只是在每次直接学习之后再进行模型学习与规划。如下图的 d、e、f 三步即为学习步骤。

图 8.2 用一个迷宫例子,表现出有模型学习在学习速度上要明显快的多。
笔记:模型实际上就是一个经验生成器,根据已经得到的经验分布,来生成一批虚拟的数据,这可能会导致过拟合,甚至还要考虑到环境在学习过程中发生变化的情况。
8.3 When the Model Is Wrong
当模型不准确时,容易得到局部最优策略。
由于 planning 得到的局部最优策略能够很快发现并修正模型的错误。
因为当模型得到的奖励比实际值还要高时,策略会倾向于探索这些没有经历过的高奖励状态,然后发现它们并不存在。
如下例,环境一开始如左图,在 1000 步后变成右图。
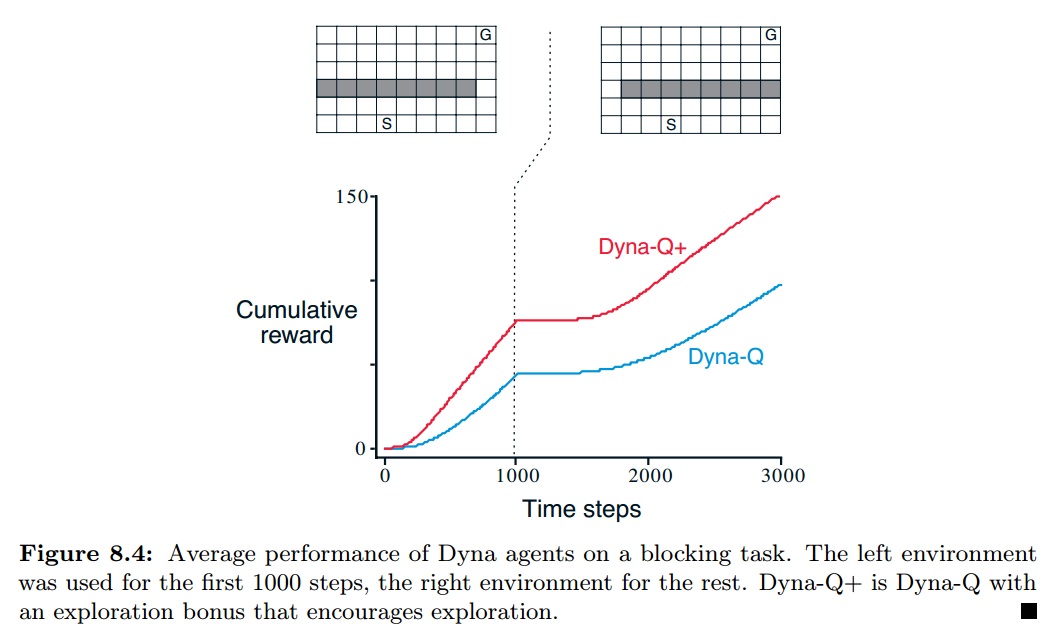
还有一个问题在于,环境发生改变后,由于模型已经严重固化,导致新的更优解会被模型忽略。 对于这种情况,算法是很难发现的,除非算法的探索性非常强。
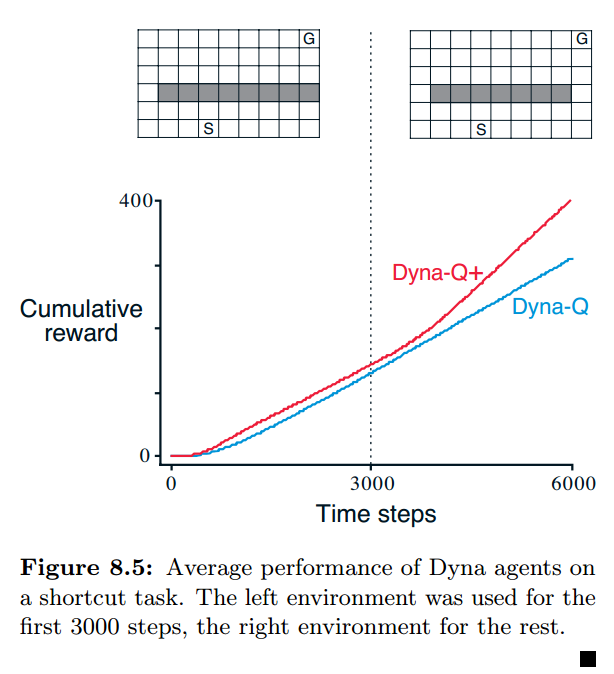
可以对太久没有尝试过的动作做一个加权奖励,以鼓励探索。
比如设置每个动作的奖励值为 $r+\kappa \sqrt \tau$ .
$r$ 为已经获得过的实际奖励值, $\tau$ 为该动作上次执行距今的步数,$\kappa$ 为鼓励系数。
### 8.4 Prioritized Sweeping ###
planning 中随机采样是没有效率的,比如例图 8.2 中的第二个 episode,在所有的状态-动作对中,仅有 terminal state 之前的状态的值是非零,其它状态值均为零,对它们进行采样并模拟,得到的结果只能是从 0 变成 0,这大量的更新都在做无用功。
状态空间越大的问题,这些无用功越多。
关于这一点需要做的是让算法的每次更新都能带来值的变化。
规划计算中的 backward focusing 是顺着已发生改变的值往前回溯,由此带来大面积的有效更新。
也即当代理修正了某个估计值后,从这个状态向前回溯,它之前的每个状态都会产生有效更新,形成一种反向传播。
Prioritized Sweeping 的思想是:一个值变化较大的状态,它的反向传播也同样会带来较大的值变化。
于是所有值的变化量作为一种优先级考虑,变化较大的状态优先更新。

在 maze 问题中,prioritized sweeping 能使算法以 5-10 倍的速度达到最优解。
prioritized sweeping 在随机环境中有其劣势,因为它用的是期望的更新(即考虑到所有可能发生的情况),如果一个低概率高变化的事件发生,那么算法会在这一系列状态上浪费巨大的计算量。
8.5 Expected vs. Sample Updates
我们讨论的各种不同的值函数更新方法中,针对 单步更新的方法,可以从三个维度来进行区分:
一是更新 状态值 还是 动作值;二是估计的值是 最优策略的,或是 任意给定策略的;三是使用 期望更新 还是 采样更新。
这三个维度组合出八种情况,其中七种可以找到对应的算法,如下图:
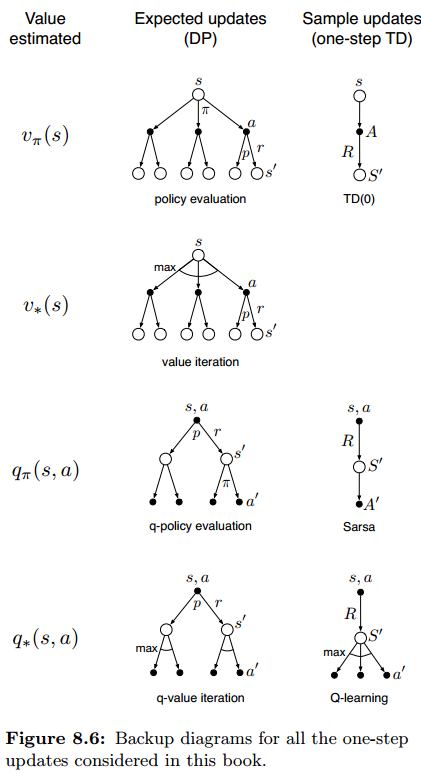
这些方法都是可以用于 planning 的。
现在考虑 expected update 和 sample update 的区别:
expected update 会考虑所有可能的 next state,这使它更加可靠,但是需要更大的计算量。
sample update 显然与之相反,只考虑一个采样的 next state,容易受到 sample error 的影响,但是计算量小得多。
两者在计算量上的区别可以做一个简单的量化,假设所有可能的 next state 的数量是 b,那么 expected update 的计算量可以看做是 sample update 的 b 倍。
如果把忽略时间因素,在足够的计算后, expected update 会比 sample update 要好,因为 sample update 是有 sample error 存在的。
但是在实际的问题中,受限于计算力,往往无法完成所有的计算,那么在权衡 expected 和 sample 中可以这样考虑:
完成一次 expected update 相当于 完成 b 次 sample update,对比 一次完整的更新 和 b个值的改善,我们往往会选择后者。
图 8.7 表现出 expected update 和 sample update 在不同 b 下的效果:
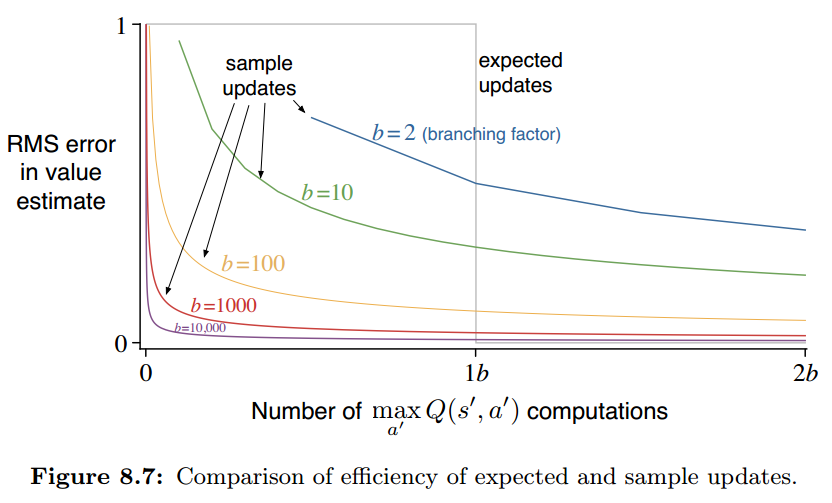
可以看到 b 越大,sample update 在前期的优势就越明显。
在实际问题中,sample update 的优势体现得更加明显,而由于更快地得到精确的估计值,又能反向传播使得其前面的状态值变得更加精确。
在具有庞大的随机分支或状态空间的问题中, sample update 的优势体现得非常明显。
8.6 Trajectory Sampling
分散更新有两种方法,一种是在 DP 中用到的 sweep,遍历整个状态空间,在状态空间很大的情况下,这种方法非常糟糕。
另一种是根据某种分布对状态空间采样,比如可以根据当前策略进行分散更新,这种分布很容易生成,直接用策略与环境或模型交互即可得到采样。
而这种采样方法可以说是沿着一条明确且独立的轨迹模拟并执行更新,这种产生经验并更新的方法叫做轨迹采样(trajectory sampling).
除了 trajectory sampling 外,想要想出一种从当前策略的分布进行分散更新的有效方法都是很难的,从这个角度来看,trajectory sampling 显得很牛。
根据当前策略分布生成经验有好有坏,好处在于它能忽略掉那些状态空间中不常出现的情况,更快地做出有效更新;
坏处则是从长远来看,它会重复地更新那些当前策略感兴趣的部份,导致有效更新越来越少,探索性不足。
8.7 Real-time Dynamic Programming
Real-time Dynamic Programming, RTDP 是动态规划的值迭代算法的一种当前策略轨迹采样版本。
当轨迹仅从有限的某些状态开始,那么在某个给定的策略下,当前策略采样可能会跳过很大一部分状态,而关注于小部分可以达到的状态。
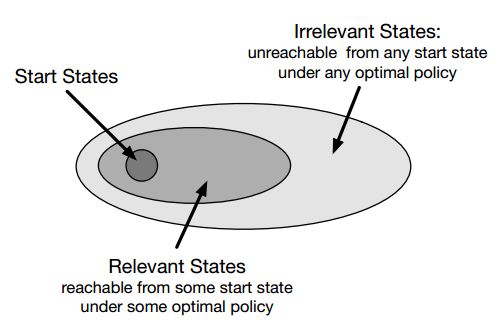
这时那些无法到达的状态就不需要求解最优动作,我们就可以关注于 optimal partial policy,仅与当前相关的状态子集的最优策略。
但是,光是找到这个 optimal partial policy 一般却需要访问整个状态空间无数次才有可能得到,这可以用探索起点做到。
在某些满足合理条件的特定种类问题中,RTDP 可以在不用遍历整个状态空间的前提下,保证找到一个局部最优策略。甚至于,它只需要访问很小一部分状态就能找到局部最优策略,这在具有超大状态空间的问题中是一个巨大的优势。
该结果出现在终结状态的奖励值为 0 的情节式(episodic)任务中,在这种任务中,RTDP 能以概率 1 使所有相关状态的值最优。
任务需要满足的条件有:
- 所有目标状态的初始值都为 0.
- 至少存在一个策略,能够保证从任意的初始状态出发,最终都能达到目标状态。
- 所有从非终结状态开始的状态转移的奖励值均为严格的负值。
- 所有的初始值都大于等于其最优值。(全部初始化为 0 就可以)
该结论由 Barto,Bradtke,and Singh 于 1995 年证明。
他们将同步 DP 的结果和启发式搜索算法(如 learning real-time A*)结合而得。
随机最优路径问题(stochastic optimal path problems)就拥有这些属性,相对于我们常做的奖励最大化,这类问题的表达是代价最小化。
8.8 Planning at Decision Time
Planning 有两种用法,一种是我们至今用的,利用(表格或逼近函数)来选择动作。
对任何当前状态 $S_t$ ,在动作被选定之前,planning 就已经为许多状态(包括 $S_t$)选择了动作,从而优化了(表格或逼近函数)。
这种方式的 planning 所关注的不是当前状态,我们称之为背景规划(background planning)
另外一种方式则是在遇到一个新的状态 $S_t$ 后,为它选择一个动作 $A_t$,然后得到下一个状态 $S_{t+1}$,继而选择下一个动作 $A_{t+1}$. 而选择动作的依据,最简单方法的是对比下一个状态的值。更常见的方法则会看到超过一步的,不同的预测状态和奖励的轨迹。
这种聚焦于某个特定状态的 planning 方式,称作决策时规划(decision-time planning).
即:一是利用仿真经验来逐渐优化策略或值函数;二是利用仿真经历来为当前状态选择动作。
这两种方式能够以自然且有趣的方式混合使用,但是现在先进一步了解 决策时规划。
在使用模拟经验来更新值、更新策略的时候,算法关注的仅仅是当前状态的值、动作选取,在选完动作后,整个 planning 过程被自然地丢弃了。
在许多应用中这不是一个多大的损失,因为状态空间太大,导致重复利用经验的情况较少,所以在很长的一段时间内不太可能遇到同一个状态。
不过我们也可以将这些经验存下来,在后面遇到同样状态时进行重复地利用。
在一些对决策时间不敏感的任务重,比如象棋,每步决策的时间都比较充裕,就可以利用这部分时间做大量的 planning 运算。
8.9 Heuristic Search
这节没看懂,后面再回顾
在人工智能中的经典状态空间规划方法就是 决策时规划,如大家熟知的启发式搜索(heuristic search)
在启发式搜索中,对每一个遇到的 state,都会给出所有可能后续变化的一个庞大的搜索树。
从叶子节点向上回溯至当前状态所在的根节点,估计值函数用在了整个路径上。
这和之前用到的使用 maxes 的 expected updates 是一样的。
计算完这些值,得到当前最优的动作后,这些备份值就被全部丢弃。
在传统的启发式搜索中,没有通过改变估计值函数来保存备份值。
实际上,值函数一般是由人设计的,并且不会因搜索结果而改变。
前面的贪婪法可以看做是一种启发式算法。
关键点在于深入搜索可以得到更好的动作选择。
搜索的步数越长,选中的动作会越好,但是耗费的计算量就越大,时间就越长。
可以以类似的方法更改更新的分布,
跳过
8.10 Rollout Algorithms
模拟一连串开始于当前环境状态的经验轨迹,使用 Monte Carlo 控制法,得到的就是一种决策时规划方法:rollout algorithms.
该算法在给定的策略下,针对某个 action,给出大量的开始于该 action 的经验轨迹,以得到的回报均值来作为该 action 的估计值。
当认为某个 动作值足够精确时,就以执行该动作,得到 next state,然后开始新的一轮估计。
rollout algorithms 的目标是在给定策略(rollout policy)下,针对当前状态,给出动作估计值。
而在得到动作估计值,执行最优动作后,进入下一个状态,之前计算的估计值就会被丢弃。
这使得 rollout algorithms 变得简单,它不需要对每个 state-action 组合进行采样,也不需要遍历状态空间来估计值函数。
8.11 Monte Carlo Tree Search
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)是一种卓有成效的决策时规划方法。
它基于 rollout algorithm ,将 Monte Carlo 模拟过程得到的值估计累积下来,以让后续的模拟轨迹达到更高的奖励。
MCTS 已被证实在一般的棋类游戏中能起到极好的效果(将 AlphaGo 从05年的业余级提升到15年的国手级的主要功臣)。
实际上,在拥有一个简单的能够进行快速多步模拟的环境模型下,来解决单代理的序贯决策问题,MCTS 都效果极佳。
MCTS 与 rollout algorithm 相同,在面对一个 state 时,通过模拟经历选择动作进入下一个状态,再递归进行该过程。
MCTS 的核心在于,它将早期模拟中得到较高评价的那些轨迹的初始部份扩展了,以此来连续关注于起始于当前状态的多步模拟过程。
模拟轨迹的大部分动作选取用的是一个简单的策略(rollout policy),而由于 rollout policy 和 模型本身需要的计算量都很小,所以在短时间内能够生成大量的模拟轨迹。
与其它 Monte Carlo 方法相同,state-action 对的值使用回报均值来估计。
仅有那些在接下来几部内大概率达到的 state-action pairs 会被保存下来,如此形成了一棵以 current state 为根的树:
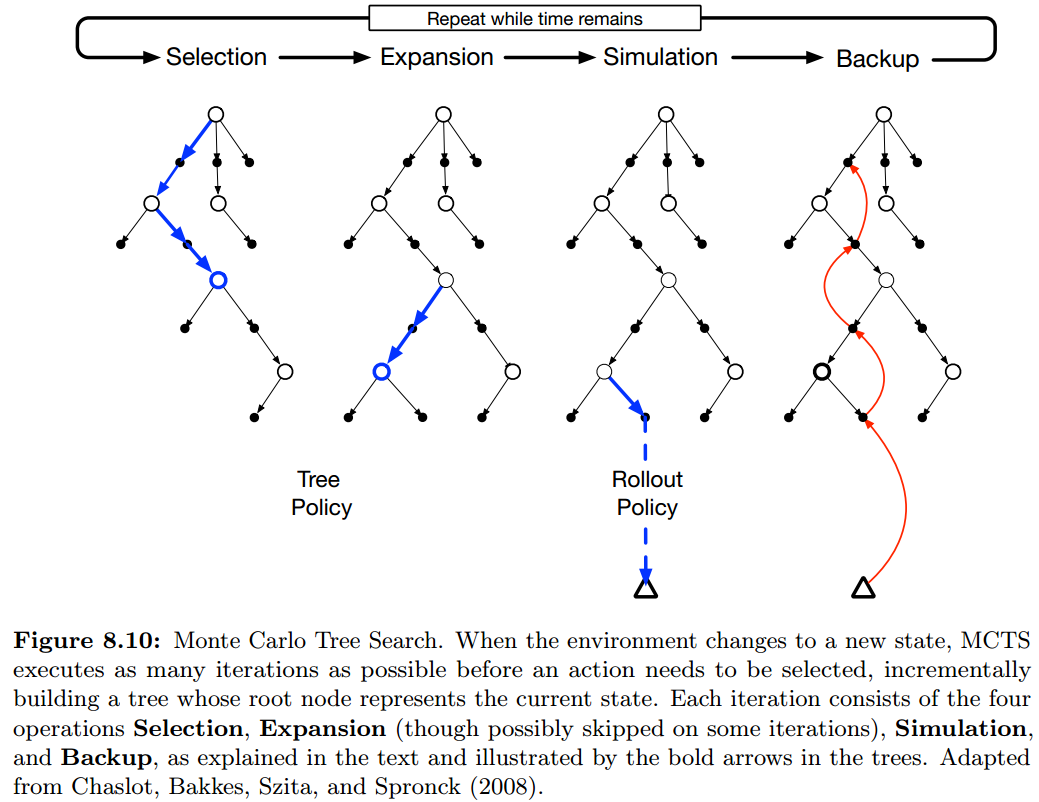
MCTS 会通过增加节点来扩展这棵树,基于模拟轨迹的结果,将那些看上去有前景的状态节点添加到树上。
每一条轨迹都会经过这棵树,并从某个叶子节点退出。
在树以外,以及树的叶子结点部份,用 rollout policy 选取动作,而在树中的节点,则使用其它更好的方式。
对于树中的状态,我们拥有至少部份动作的估计值,所以会使用一个更聪明的策略(tree policy)来选取它们。
比如,用 $\epsilon$-greedy 或 UCB 作为 tree policy.
基本的 MCTS 的每一轮迭代都会包含以下四个步骤:
- Selection. : 从根节点开始,使用一个基于树的边的动作值的策略 tree policy,来穿过这棵树,选中一个叶子节点。
- Expansion. : 在某些迭代中(取决于应用的细节),在选中的叶子节点处,添加一个或多个未被探索过的动作,扩展这棵树。
- Simulation. : 从选中的叶子节点(或其添加的某个子节点)开始,用 rollout policy 选择动作,进行一遍完整的 episode. 这样的结果就是一次 Monte Carlo 试验中,一开始用 tree policy 选动作,而后使用 rollout policy 选。
- Backup. : 模拟 episode 产生的回报用于反向更新,或用于初始化树中在这一轮被走过的边的动作值。在树外由 rollout policy 访问过的节点的值都被丢弃。
MCTS 重复这四个步骤,直到某些计算资源耗尽,或者达到决策时间。然后从根节点(表示当前状态)选择动作,可能是选择具有最大值的动作,也可能选择被访问次数最多的动作(避免选到树外去),这个动作是 MCTS 真正选的动作。
在环境转移到新的状态后,MCTS 再次运行,有时会从一个新的根节点开始,但更多的是从上一轮的树中的某个子节点开始的,剩下的其它节点包括相关的值都被丢弃。
MCTS 是基于蒙特卡洛控制的一种决策时规划算法。
它结合了 在线、递增、基于采样的值估计与策略优化。此外,它将树中的边表示的动作值保存下来并用 RL 的采样更新来更新它们,这使得蒙特卡洛试验集中在模拟轨迹上,轨迹的前面部份和上一轮模拟得到的高回报的轨迹是一致的。
此外,通过逐步扩展决策树,MCTS 有效地扩展了其查找表,且该表始终关注着具有高回报的样本轨迹的初始部份,这让内存等资源都能关注于最有用的信息。并由此避免了去全局地估计一个值函数的窘境,同时保留了使用过去经验来指导探索的好处。
MCTS 的巨大成功对人工智能领域产生了深远的影响。