本章介绍有限马尔科夫决策过程(finite MDPs)
MDPs 是序贯决策(sequential decision making)的一种经典形式,即行为不仅影响到立即奖励,还会对后续的状态造成影响,导致未来所获奖励的变化。
因此 MDPs 涉及了延迟奖励(delayed reward),需要在立即奖励与延迟奖励间做 trade-off.
正如在 bandit problems 中为每个 action $a$ 估计其 value $q_\ast (a)$ 一般,在 MDPs 中会为在每个 state $s$ 所做的 action $a$ 估计其 value $q_\ast (a)$ ,或为每个状态的 optimal action 估计其 value $v_\ast(s)$ ,这些与状态相关的值在为每个独立的动作选择分配其所造成的长远后果的权重时至关重要。
MDPs 是那些可做精确理论表述的 RL 问题的最理想的数学形式;
如所有人工智能问题一样,可用性和易计算性也是一对需要权衡的矛盾。
3.1 The Agent-Environment Interface
RL 问题是通过交互学习达到一个目标,MDPs 是对这种问题的最简洁的表达。
- agent:学习和做出决策
- environment:agent 的交互对象,除了 agent 以外的一切
agent 和 environment 的交互是持续的,agent 选择 actions ,environment 根据 action 给出新的 state
environment 也会给出 rewards ,rewards 是 agent 需要通过不断决策来提高的一个数值
agent 与 environment 在每个离散时间步 $t=0,1,2,3,\dots$ 做交互(离散使问题变得更简单)
在每个 $t$ ,agent 接收 environment 的状态 state, $S_t \in \mathcal S$ 并基于此选择一个 action,$A_t \in \mathcal A(s).$ 在下一步,作为 action 的结果, agent 会收到一个数值 reward, $R_{t+1} \in \mathcal R \subset \mathbb R$ ,并发现状态发生了改变(进入 $t+1$ ),得到 $S_{t+1}$.
交互轨迹:
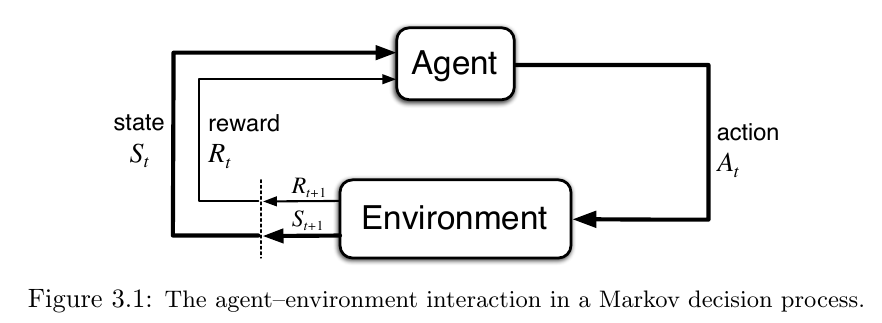
在一个 finite MDPs 中,states,actions 和 rewards 取值的集合($\mathcal S, \mathcal A, and\ \mathcal R$)中的元素个数都是有限的。
在这种情况下,随机变量 $R_t$ 和 $S_t$ 有明确定义的离散概率分布,且仅依赖于前一个 state 和 action.
即对于这些随机变量,出现在时间 $t$ 的具体值,$s’\in \mathcal S$ 和 $r \in \mathcal R$ ,有一个概率:
条件概率在此处表明对于所有的 $s \in \mathcal S,\ a\in \mathcal A(s).$,其概率和为 1:
四参函数 $p$ 完整地表述了一个有限马尔科夫决策的动态过程。利用它能够计算关于 environment 的一切其它信息。
比如状态转移概率(state-transition probabilities):
又如一对 state-action 的期望奖励:
还有一组 state-action-(next-state) 的期望奖励:
对于 RL 中的 agent 和 environment 在实践中该如何界定:
agent-environment 的界限表现为 agent 所能绝对控制的部分限制,而不是它所掌握的知识限制
不同任务之间的 states 和 actions 变化很大,如何表示它们会对性能造成非常大的影响。
现如今,在强化学习和其它学习方法中,特征表示方式的选择更像一种艺术而非科学。
本书主要关注学习的方法,而不是特征表示。
Exercise
3.1:
- 拳皇游戏,目的是控制一个游戏角色打败对手:states 就是画面,或者更精细些,双方的人物角色,血量,气量,位置,当前动作;actions就是操作的那些动作,前后左右、轻重拳脚等;rewards当然是最后的胜利给出一个超大的reward,当然每次让对方掉血也可以相应的给出reward,且可以随对方血量降低而逐渐提高等。
- 围棋,目的就是获胜:states 就是棋盘上的情况,哪些棋子在哪些位置;actions 就是把棋子落在哪里;rewards 如上,可以在最后胜利时给出超高的reward,每次落子后得到的地、势没有上面的那么明显,可能需要其它方法来估测。
- 机器人,目的是控制一个机器人让他走一段距离:states 就是那些传感器能够感知到的机器人的各个部位的情况,包括位置、速度、受力等等;actions 就是控制各个电机的信号;rewards 就是机器人走到目标位置时给出一个超高的reward ,其它情况比如靠近一些就给一些,还能给它加点能耗的限制,比如消耗能源高的话,得到的reward 就少些。
3.2:
待做
3.3:
这得看怎么实现驾驶的功能,如果 agent 设置为汽车的控制系统,具备直接控制汽车离合、刹车等,那么界限就是第一种啦;如果是将 agent 作为一个机器人,就像人一样操控汽车,踩离合、刹车、换档的话,那就类似于大脑控制肌肉的方式了。
其实哪种方式都可以理解,但是很显然,越接触底层越好达成目标,最好就是 agent 能够直接控制轮胎、发动机等,这可以避开很多中间的问题。比如稍微高层的控制,像设计一个机器人像人一样踩刹车、油门的话,其实它的目的就不仅仅局限于驾驶了,而是一个机器人的控制问题,操控机器人的肢体做出什么样的动作,然后做出这个动作能够达成怎样的操纵效果,最终传递到汽车上会是怎样的行驶效果。
中间的环节越多,带来的问题就越多,所以在设计 agent 和 environment 的时候,应该看具体的场景,越接近底层越容易达成目标。
3.4:这就是把四参函数 $p$ 中的三参去了,只剩下了 $s$ 一个参数,又因为策略 $\pi$ 是随机的,那么 $a$ 就由 $\pi$ 按概率给出,参考二参函数 $r(s,a)$ ,可以写出:
3.5:
| $s$ | $a$ | $s’$ | $r$ | $p(s’,r\mid s,a)$ |
|---|---|---|---|---|
| high | search | high | $r_\mathrm{search}$ | $\alpha$ |
| high | search | low | $r_\mathrm{search}$ | $1-\alpha$ |
| high | wait | high | $r_\mathrm{wait}$ | $1$ |
| low | search | high | $-3$ | $1-\beta$ |
| low | search | low | $r_\mathrm{search}$ | $\beta$ |
| low | recharge | high | $0$ | $1$ |
| low | wait | low | $r_\mathrm{wait}$ | $1$ |
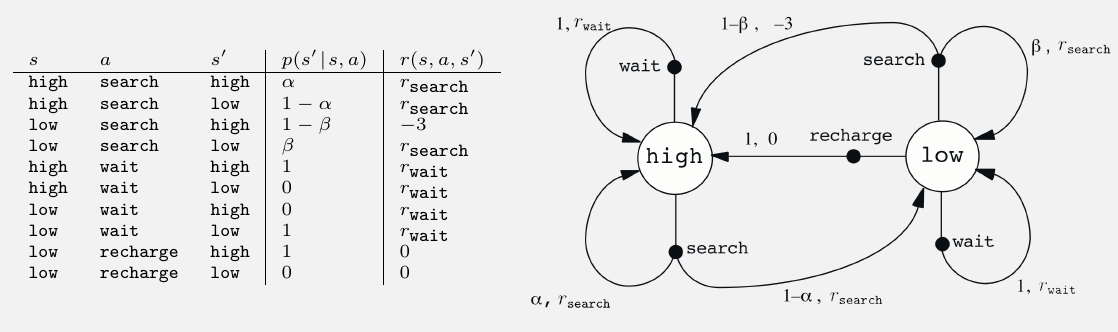
Example 3.3 Recycling Robot
一个在办公场所收集废弃易拉罐的移动机器人。它有检测易拉罐的感知器,有能捡起罐子丢进垃圾桶的手臂和夹子;使用可充电电池。
设其状态集 $\mathcal S={\mathbb{high,\ low}}$. 表示电量的高低
动作集分为 $\mathcal A(\mathbb{high})={\mathbb{search,\ wait}}$ 和
$\mathcal A(\mathbb{low})={\mathbb{search,\ wait,\ recharge}}$
其中,search 表示主动寻找易拉罐, wait 表示等待有人把罐子送到它面前,recharge 表示返回充电。
其中,回收易拉罐会带来较高 reward ,但是 search 行为会耗费较大电量,当电量耗尽时将关机等待回收。
search 的期望奖励大于 wait 的期望奖励 $\mathcal r_\mathrm{search}>\mathcal r_\mathrm{wait}$ ,而 recharge 的奖励为 0 ,电量耗尽被关机回收的奖励为 -3.
各状态的转移概率及奖励如下:
3.2 Goals and Rewards
在 RL 中,agent 的目标被数值化为 reward $R_t\in \mathbb R$,由 environment 传给 agent
非正式的,agent 的目的是最大化其所获得的 reward 之和
可以用奖励假设(reward hypothesis)来描述:
- 我们的目标可以用最大化一个期望来表示,该期望为所受到的数值信号(reward)的累计和的期望值
使用一个奖励信号来表示目标,是 RL 的最鲜明的特点
这样表示目标看上去很局限,但在实际应用中却被证明是灵活且泛用的。
reward 应当告诉 agent 它要做成什么,而不是它要怎么做。
3.3 Returns and Episodes
agent’s goal 的正式定义:最大化一个期望回报(expected return) $G_t$ ,其最简单的情况:
此处 $T$ 为最后一个时间步,称为 terminal state,在 agent-environment 之间的交互自然地终结时(比如棋局分出胜负),这一整个过程称作 episode
在这种 episodic tasks 中,有时需要区分有无 terminal state 的状态集: $\mathcal S$ 和 $\mathcal S^+$.
$T$ 是一个随机变量,在不同的 episode 中是随机的。
与之相反的,continuing tasks 是不会自然终结的任务,比如一个任务周期很长的机器人,此时其 terminal state $T=\infty$ ,那么回报也很自然的无穷大。
使用折扣(discounting)来定义回报:
$0\leq \gamma \leq 1$,是一个参数,叫做折扣率(discounting rate)
如果 $\gamma < 1$ ,那么 $G_t$ 就是有界的,如果 $\gamma =0$ ,那么 agent 就是短视的,它只会看到立即奖励,对后续的影响一概不管; $\gamma$ 越大, agent 考虑得越远。
连续时间下,相邻回报的关系在 RL 理论与算法中十分重要:
在 $t<T$ 时,上式成立,即使假设 $t=T+1$ ,我们也可以使 $G_T=0$ 来让 return 更易计算。
回报由无穷项 reward 累加得到,但在 $\gamma < 1$ 的情形下,回报一般也是有限的,比如假设 reward 始终为 +1,则:
Exercise
3.6:
3.7:
回报值在 $T$ 以前都为 0 ,在 $T$ 时为 -1 ,然后结束,开始下一个 episode
continuing 中在 failure 发生后,任务会继续进行,也就是每次 failure ,回报 -1 ,那么随着failure 的累计,回报越来越小, agent 会学习使回报减小的速度越来越慢,直至不再减小
两者的任务目标发生了变化, episodic 形式在每次 failure 后会重置环境,那么其任务目标就主要是让棒子保持直立,不会倒下;而 continuing 形式在 failure 后不会重置,那么显然在一开始 failure 是非常容易出现的,那么其任务目标就主要是让倒下的棒子立起来,并保持直立。
两者的任务目标有很大的变化,后者看上去会更难一些,它实际上包含了前者的任务目标-保持直立,另外再加上一个重新立直的目标
但是实际使用中未必就后者更难实现,因为 continuing 任务中,基本上每一步都是一次failure,其可学习的数据是不停出现的,而在 episodic 任务中,则是每一次 episode 结束才会出现回报的变化,学习速度未必就比 continuing 要快,不过这个有待实验。
3.8:
这取决于迷宫的情况,如果是一个很小的迷宫,agent 尝试个几次就能找到出口,那么这种方法并没有问题;
但是如果迷宫稍微大些,agent 经过很长一段时间的尝试,都找不到出口,其收到的 reward 始终是 0 ,没有任何的改善,它也就学不到任何的知识,始终在做着无意义的探索,且很有可能在有限的地方不断重复;
这种情况可以让 agent 做更广泛的探索,比如根据 state 给出 reward ,让 agent 去探索那些 state 出现次数比较少的地方,如果是从未出现过的 state ,就给他较高的 reward ,这样 agent 可能会先学会寻找没有走过的地方;
那么当它探索的新环境足够多的时候,也就应该能够找到出口了;
如此避免了 agent 在几个地方不断重复地做无用功。
3.9:
3.10:
3.11:
3.4 Unified Notation for Episodic and Continuing Tasks
episodic tasks 计算相对简单,因为每个 action 仅影响当轮 episode 中的有限的 rewards;
为 episodic task 和 continuing task 建立一个统一的公式;
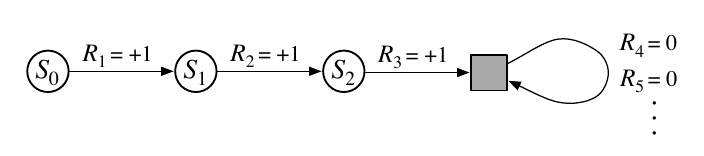
将 episode 的terminal state 视作一个特殊的 absorbing state ,它只会转移到自己,且获得的 reward 为 0。
引入 absorbing state 后, $G_t$ 的无穷形式和有穷形式就统一了,包括 $T=\infty$ 和 $\gamma=1$ (两种同时存在则不成立)等情况:
3.5 Policies and Functions
几乎所有的 RL 算法都会涉及到估计值函数(value functions),值函数用来表示一个 state(或一对 state-action) 有多好,能够在未来得到多少的 rewards
而 rewards 又取决于 agent 所选的 action,因此,值函数的定义是 决策模型 即策略的一种特定形式。
策略(policy) 是从 states 到选择 action 的概率的一个映射
一个 agent 按照策略 $\pi$ 在时刻 $t$ 做出决策,那么 $\pi(a\mid s)$ 则是在 $S_t=s$ 的情况下, $A_t=a$ 的概率
而 RL 方法则是用于指定 agent 的 policy 要如何利用经验来调整
state-value function for policy $\pi$, $\mathcal v_\pi(s)$ 定义为从 $s$ 开始遵循策略 $\pi$ 所得到的期望回报 returns:
terminal state 的 value 总为 0
action-value function for policy $\pi$ ,类似的,有 $q_\pi(s,a)$ ,定义为从状态 $s$ 开始,选择动作 $a$ 得到的期望回报 returns:
值函数可以通过经验来估计
比如,一个 agent 遵循策略 $\pi$ 对每一个经历的状态,都将其值函数定为其后续所收到的实际回报的均值,那么这个均值在足够多次经历这个状态后,就会收敛在其实际值处
这种估计方法称作 Monte Carlo methods ,因为其涉及对实际回报的多次随机采样的平均
值函数与回报类似,满足一个递归关系,这在 RL 和动态规划中十分重要:
上式最后一行是 Bellman equation for $\mathcal v_\pi$ ,表现了一个状态与其可能的后续状态之间的 value 值的关系
Exercise
3.12:
3.13:此处考虑 $a’$ 而非 $a$ 即可:
3.14:
所有的 reward 值加上一个常数 c ,会使得所有的回报值加上常数 $c/(1-\gamma), \gamma \neq 1$ , 不会影响到各回报值之间的大小关系,不过可能会对 greedy-action 的选择概率造成改变。
3.15:
对 episodic task 的所有 reward 值加上常数 $c$ 后,其所有的回报值会多出一个 $c\frac {1-\gamma^{T-t-1}}{1-\gamma}$ ,显然这个值受到 $\beta=T-t-1$ 大小的影响; 越接近 terminal state 的时候,$T-t$ 越小,$\beta$ 越小,回报值的变化就越小;
极端情况举例:当 $t=T-1$ 时 ,也就是马上将要完成一个 episode 的时候,$\beta=T-t-1=0$ ,此时 $\Delta G_t=0$ ,而离 terminal state 足够远时,回报值的变化可以看做与 continuing task 中的相同 $c/(1-\gamma$)
那么我们可以得到的结论:如果把所有 reward 值都设得很大的话,即 $c$ 很大,那么那些越接近 terminal state 的状态,其对应的 return 值就会相对那些远离 terminal state 的要小的多。
直觉的理解就是,当每个动作带来的 reward 都很大的话,那些较早做出的动作会影响到较多的状态,所以能够有比较大的回报值,而那些越晚做出的动作,相对影响到的状态就会少些,得到的回报就会少些。
Exercise
3.16:
3.17:
3.6 optimal Policies and optimal Value Functions
解决 RL 问题,就是要找到一个能够获得大量累计奖励的策略 policy;
对于 finite MDPs ,能够精确地定义一个最优 policy
value functions 对 policies 定义部分排序
如果一个策略 $\pi$ 在所有的状态 states 下,其期望回报 return 均大于或等于另一个策略 $\pi’$ ,那么就称 $\pi$ 优于 $\pi’$
用数学语言表达就是: $\pi \geq \pi’\ if\ and\ only\ if\ \mathcal v_\pi(s)\geq\mathcal v_{\pi’}(s)\ for\ all\ s\in \mathcal S$
总是会有至少一个策略会优于或等于所有其它的策略,称之为最优策略(optimal policy),将它或它们统一定义为 $\pi_\ast$ ,它们共享相同的 state-value function ,称为最优 状态-值 函数(optimal state-value function),写作 $\mathcal v_\ast$ ; 同理有最优 状态-动作-值 函数 $\mathcal q_\ast(s,a)$ ,它们的定义如下:
贝尔曼最优方程(Bellman optimality equation)表现出:在最优策略下,一个状态的 value 必须等于该状态的最优 action 的期望回报:
状态-动作 值函数的贝尔曼最优方程:
对于有限马尔科夫决策过程,$\mathcal v_\ast(s)$ 的贝尔曼方程有独立于策略的唯一解
贝尔曼方程实际对每个状态都是一个方程组,那么 n 个状态就有关于 n 个未知数的 n 个等式
如果环境动态 $p$ 已知,那么原则上就能够用解非线性方程组的方法解出关于 $\mathcal v_\ast$ 的方程组,继而解出关于 $q_\ast$ 的方程组
一旦有了 $\mathcal v_\ast$ ,就很容易得到一个最优策略
对于每个状态 $s$ ,会有一到多个拥有最大值的 action ,只要简单地只选择这些 actions 就能得到一个最优策略,即一个简单的贪婪策略就是最优策略,仅仅是做了一个单步搜索
$\mathcal v_\ast$ 的妙处就在于,它考虑了未来可能的长期回报
如果有了 $q_\ast$ ,问题会变得更加简单,它连单步搜索都不需要做,对任何状态 $s$ ,都能轻易的找到一个使得 $\mathcal q_\ast(s,a)$ 最大的 action ,它本身就包含了单步搜索的结果
Example 3.8: Bellman Optimality Equations for the Recycling Robot
同上可得:
对于任意一组满足 $0\leq \gamma <1,\ 0\leq \alpha,\ \beta \leq 1$ 的 $\mathcal r_s,\ \mathcal r_w,\ \alpha,\ \beta,\ and\ \gamma$ , 都有一组确切的 $\mathcal v_\ast(h)$ 和 $\mathcal v_\ast(l)$ 同时满足以上的非线性方程
很显然,贝尔曼最优方程给出了一条找到一个最优策略的道路,从而解决 RL 问题
但是,这个方法很难直接起作用
它就像是穷举法,穷举所有的可能,计算出它们的期望奖励的概率和取值
这个方法需要至少满足三个条件,而这三个条件在实践中很难同时成立:
- 准确知道环境动态 $p$
- 拥有足够的算力来完成这些计算
- 马尔科夫特性
举个例子:西洋双陆棋(backgammon) 满足了条件 1 和条件 3 ,但是它包含了 $10^{20}$ 种状态,以现如今最好的计算机而言,也要数千年的时间才能完成这么大的计算量,找到贝尔曼方程的 $\mathcal v_\ast$
在 RL 问题中,我们只能用 逼近解法
许多决策方法都可以看做对贝尔曼方程的近似解法
比如启发式搜索可以看做对式 3.19 的右边不断拆解,达到一定深度后形成一个概率树,然后使用启发式评估函数来逼近叶子节点的 $\mathcal v_\ast$
Exercise
太多了,先跳过
3.7 Optimality and Approximation
算力的限制:
计算得到 $\mathcal v_\ast$ 需要的算力太大,对于实际应用不太可能实现
agent 面临的问题的一个关键方面始终是可用的计算能力,特别是它可以在单个时间步长中执行的计算量
内存的限制:
tabular case:状态集较小的问题,可以用数组或表来存储每个状态的近似值
但是对于稍大些的状态集,就只能用更紧凑的逼近函数来表示
RL 方法的在线学习特性使得,它在那些频繁出现的状态中用功,而那些很少出现的状态则被简略掉,由此来逼近最优策略
这是 RL 方法和其它 MDPs 的逼近解法 的重要区别
3.8 Summary
RL 通过交互来学习如何决策以达成某个目标
agent 和 environment 在一序列离散时间步上做交互
actions 是由 agent 做出的选择
states 是做出这些选择的 依据
rewards 是评价这些选择的 依据
agent 内的一切都是完全可知且可控的
agent 外的一切都是完全不可控的,可能完全可知,也可能不完全可知
policy 是一种随机规则,作为状态的一个函数,供 agent 选择 actions
agent 的目标是最大化随时间可获得的 reward 总和
上面描述的 RL 要素与其之间的概率转移构成了一个 MDP
finite MDP 则是拥有有限集 state、action 和 reward 的 MDP
RL 的很多理论都限制在 有限 MDPs 中,但是方法的使用能够更泛化
return 是 agent 要最大化的关于未来奖励的函数
无折扣的回报形式更适合 episodic tasks,这类任务会自然地在某种情况下停止 agent-environment 的交互
折扣形式的回报更适合 continuing tasks, 这类任务则不会自然结束,有可能无限制(或看上去无限制)地持续下去
policy 的 value functions 会给每个 state 或 state-action 对赋值,其值表示了 agent 使用这个 policy 从该状态开始所能得到的期望回报
optimal value functions 则是赋予了最高的期望回报,不管 agent 所用的 policy 是哪个
一个拥有 optimal value functions 的 policy 就是 optimal policy
一个给定的 MDP 具有唯一的 optimal value functions ,但是存在多个 optimal policy
任何一个根据 optimal value functions 使用 greedy 决策方法的 policy 都必然是 optimal policy
贝尔曼最优方程是 optimal value function 所必须满足的一致性条件,原则上,能由它接触 optimal value functions ,并由此得到 optimal policy
一个 RL 问题依据其 agent 可知的初始知识的级别,会有不同的表现方式
complete knowledge 表示环境动态是完全可知且精确的,在 MDP 中则意味着四参函数 $p$ 是已知的
incomplete knowledge 表示完整且完美的环境模型是不可得的
即便 agent 拥有了 完整且精确 的环境模型, agent 通常也无法在每一步都充分利用它进行运算
内存限制也使得较大的 状态集 只能用逼近方式来构造
对最优化有个清晰的概念能够帮助理解各种学习算法的理论,虽然在实际应用中我们总是只能不同程度地逼近最优
而在 RL 实践中,我们会更加关注那些只能逼近而无法精确计算出最优解法的问题